Object Oriented Programming is about creating objects that contain both data and functions. It is based on the principles of encapsulation, inheritance, polymorphism, and abstraction.
Contents
- Advantages
- Disadvantages
- Class vs Object
- Main features of OOPS
- The Diamond Problem
- Types of Polymorphism
- Constructors
- How constructors are different from a normal member function?
- Destructor
- Can constructor be made private?
- How to use Constructors in private section?
- Access Modifiers in C++
- Scope Resolution Operator
- Namespace
- Inline functions
- Struct vs Class
- C Structures vs C++ Structures
- C vs C++
- Object-oriented programming vs Procedural programming
- Accessors and Mutators
- This Keyword
- Friend Function and Class
- Generalization and Specialization
- Is-A and Has-A
- Association, Aggregation and Composition
- Interface
- Abstract Class
- Function Overriding
- Upcasting
- Downcasting
- Virtual function
- Pure virtual function
- Early binding and Late binding
- Late Binding
- Can we make virtual constructor?
- Exception handling
- Types of Errors
- Garbage Collection in OOPs world
- Actual and Formal Parameters
- Call by Value
- Call by Reference
- Templates
- Why Java is not a purely Object-Oriented Language?
- const keyword
- lvalue and rvalue
- Preprocessors
- Shallow and Deep copy
- Global Variables
- Local Variables
- Static Data Members or Static Member Function
- How delete [] is different from delete?
- Difference between reference and pointer
- Difference between new() and malloc()
- Typecasting
- Compiler and Interpreter
- Data Types
- Operators in C++
- Tokens
- Keywords in C++
- #include<> and #include””
- High Level Language vs Low level Language
- Storage Classes
- Literals In C++
- RTTI (Run-time type Information)
- Casting Operators in C++
- Command Line Arguments
- C++ (platform-dependent) & Java (platform-independent)
- JVM Architecture
Advantages
- Modularity and Code Reusability: OOPS promotes modular programming by breaking down code into objects and classes. This modular approach allows developers to reuse code in different parts of a program or even in different projects, saving time and effort. Code reusability reduces duplication, improves efficiency, and enhances maintainability.
- Lower cost of development: The reuse of software also lowers the cost of development
- Encapsulation
- Inheritance
- Polymorphism
- Abstraction
Disadvantages
- Steep learning curve
- Slower programs: Object-oriented programs are typically slower than procedure based programs, as they typically require more instructions to be executed.
- Not suitable for all types of problems
Class vs Object
| Class | Object |
|---|---|
| Blueprint or template for creating objects | Instance of a class that represents a real-world entity |
| Contains member variables and member functions | Has a state (values of member variables) and behavior |
| No memory allocation for a class, as it is a logical concept | Requires memory allocation to store its state as it is a physical entity. |
| Class is declared once | Object is created many times as per requirement. |
| Example of class can be car. | Objects of the class car can be BMW, Mercedes etc. |
| Can participate in inheritance hierarchies, where one class can derive properties and behaviors from another class | Objects do not participate in inheritance, but they can be created from a class that participates in inheritance |
| Classes have a global scope and can be accessed from multiple parts of a program | Objects have a limited scope and are accessible within the scope in which they are defined |
Main features of OOPS
Encapsulation: Encapsulation is defined as the wrapping up of data and information in a single unit. It provides data protection and restricts direct access to internal implementation details.
#include <iostream>
using namespace std;
class temp{
int a;
int b;
public:
int solve(int n){
a = n;
b = a/2;
return b;
}
};
int main() {
int n;
cin >> n;
temp half;
int ans = half.solve(n);
cout << ans << endl;
}Abstraction: Abstraction means displaying only essential information and data to the outside world and hiding the background details. It allows developers to work at a higher level of abstraction, dealing with essential features and ignoring the unnecessary complexities.
#include <iostream>
using namespace std;
class implementAbstraction {
private:
int a, b;
public:
void set(int x, int y){
a = x;
b = y;
}
void display(){
cout << "a = " << a << endl;
cout << "b = " << b << endl;
}
};
int main(){
implementAbstraction obj;
obj.set(10, 20);
obj.display();
return 0;
}Inheritance: Inheritance is a feature or a process in which, new classes are created from the existing classes. The new class created is called “derived class” or “child class” and the existing class is known as the “base class” or “parent class”.
#include <iostream>
using namespace std;
class Base{
public:
int a;
void display(){
cout<<a<<endl;
}
};
class Derived : public Base{
public:
void show(){
cout<<a<<endl;
}
};
int main(){
Derived d;
d.a=10;
d.display();
d.show();
return 0;
}
Note: In C++ inheritance, private members of a base class are inherited into the derived class but are not directly accessible within the derived class. To access these private members, you can use one of the following methods:
- Using Getter and Setter Member Functions
- Using friend Class

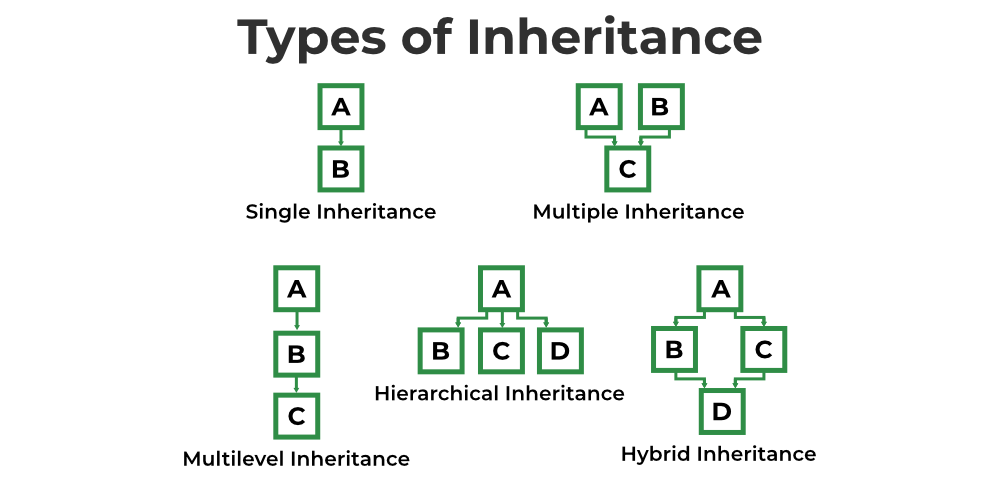
Types of Inheritance:
- Single inheritance: In single inheritance, a class is allowed to inherit from only one class.
- Multilevel inheritance: In this type of inheritance, a derived class is created from another derived class.
- Multiple inheritance: A class can inherit from more than one class.
- Hierarchical inheritance: In this type of inheritance more than one derived class is created from a single base class.
- Hybrid inheritance: Hybrid Inheritance is implemented by combining more than one type of inheritance. For example: Combining Hierarchical inheritance and Multiple Inheritance.
Note: Normally constructor calling sequence is depending on order of object declaration and destructor calling sequence is exactly opposite. But in case of inheritance, if we create object of derived class, first base class & then derived class constructor gets called. Destructor calling sequence is exactly opposite.
The Diamond Problem
The diamond problem occurs when two superclasses of a class have a common base class.

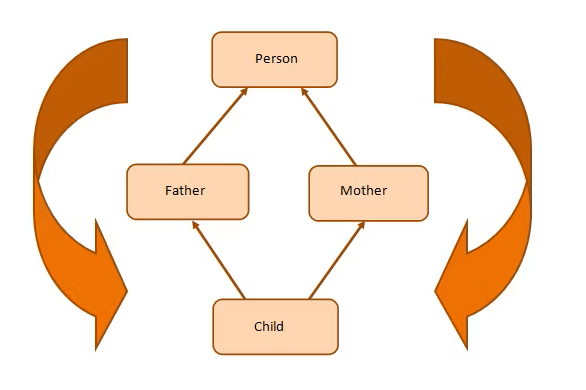
class Child inherits the traits of class Person twice—once from Father and again from Mother. This gives rise to ambiguity since the compiler fails to understand which way to go.
class Person {
public:
void speak() {
cout << "Person speaks" << endl;
}
};
class Father : public Person {
public:
void speak() {
cout << "Father speaks" << endl;
}
};
class Mother : public Person {
public:
void speak() {
cout << "Mother speaks" << endl;
}
};
class Child : public Father, public Mother {
public:
//
};
Child child;
child.speak(); // Ambiguity! Which speak method should be called?
The solution to the diamond problem is to use the virtual keyword.
class Person {
public:
virtual void speak() {
cout << "Person speaks" << endl;
}
};
class Father : public Person {
public:
void speak() override {
cout << "Father speaks" << endl;
}
};
class Mother : public Person {
public:
void speak() override {
cout << "Mother speaks" << endl;
}
};
class Child : public Father, public Mother {
public:
//
};
Another way to solve the Diamond Problem is to use the scope resolution operator (::)
class Child : public Father, public Mother {
public:
void speak() {
Father::speak();
}
};Polymorphism: The word “polymorphism” means having many forms. In simple words, we can define polymorphism as the ability of a message to be displayed in more than one form. A real-life example of polymorphism is a person who at the same time can have different characteristics. A man at the same time is a father, a husband, and an employee. So the same person exhibits different behavior in different situations.
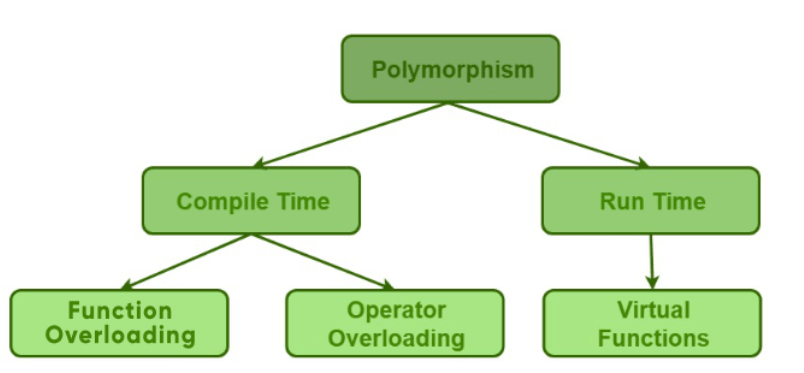
Types of Polymorphism
- Compile-time Polymorphism: Compile time polymorphism, also known as (Static Polymorphism, Static Binding, Early Binding, Weak typing, False Polymorphism), refers to the type of Polymorphism that happens at compile time. What it means is that the compiler decides what shape or value has to be taken by the entity in the picture. Method overloading or operator overloading are examples of compile-time polymorphism.
- Runtime Polymorphism: Runtime polymorphism, also known as (Dynamic Polymorphism, Dynamic Binding, Late Binding, Strong typing, True Polymorphism), refers to the type of Polymorphism that happens at the run time. What it means is it can’t be decided by the compiler. Therefore what shape or value has to be taken depends upon the execution. Method overriding is an example of this method.

Function Overloading
Function overloading is a feature of object-oriented programming where two or more functions can have the same name but different parameters.
#include<iostream>
using namespace std;
int sum(float a, int b){
cout<<"Using function with 2 arguments"<<endl;
return a+b;
}
int sum(int a, int b, int c){
cout<<"Using function with 3 arguments"<<endl;
return a+b+c;
}
// Calculate the volume of a cylinder
int volume(double r, int h){
return(3.14 * r *r *h);
}
// Calculate the volume of a cube
int volume(int a){
return (a * a * a);
}
// Rectangular box
int volume (int l, int b, int h){
return (l*b*h);
}
int main(){
cout<<"The sum of 3 and 6 is "<<sum(3,6)<<endl;
cout<<"The sum of 3, 7 and 6 is "<<sum(3, 7, 6)<<endl;
cout<<"The volume of cuboid of 3, 7 and 6 is "<<volume(3, 7, 6)<<endl;
cout<<"The volume of cylinder of radius 3 and height 6 is "<<volume(3, 6)<<endl;
cout<<"The volume of cube of side 3 is "<<volume(3)<<endl;
return 0;
}Operator Overloading
Operator overloading is a compile-time polymorphism in which the operator is overloaded to provide the special meaning to the user-defined data type. In C++, also we can not use operator with objects of user defined type directly. If we want to use operator with objects of user defined type then we should overload operator.
We can define operator function using 2 ways:
- Using Member Function: If we want to overload operator using member function then operator function should take only one parameter and operator function must be member function.
- Using Non-Member Function: If we want to overload binary operator using non member function then operator function should take two parameters and operator function must be global function.
// Operator function as member function of a class
#include <iostream>
using namespace std;
class Complex {
private:
int real;
int img;
public:
Complex(int r = 0, int i = 0) {
real = r;
img = i;
}
void display() {
cout << real << " + i" << img << endl;
}
// Overloading the + operator to add two complex numbers
Complex operator+(Complex x) {
Complex temp;
temp.real = real + x.real;
temp.img = img + x.img;
return temp;
}
};
int main() {
Complex c1(5, 10), c2(3, 4), c3;
c1.display();
c2.display();
// Using the overloaded + operator to add objects c1 and c2
c3 = c1 + c2;
// c3 = c1.operator+(c2);
c3.display();
return 0;
}// Operator function as non-member function of a class (global function)
#include <iostream>
using namespace std;
class Complex {
private:
int real;
int img;
public:
Complex(int r = 0, int i = 0) {
real = r;
img = i;
}
void display() {
cout << real << " + i" << img << endl;
}
// Declaring the non-member function as a friend of the class
friend Complex operator+(Complex &x, Complex &y);
};
// Overloading the + operator to add two complex numbers
Complex operator+(Complex &x, Complex &y) {
Complex temp;
temp.real = x.real + y.real;
temp.img = x.img + y.img;
return temp;
}
int main() {
Complex c1(5, 10), c2(3, 4), c3;
c1.display();
c2.display();
// Using the overloaded + operator to add objects c1 and c2
c3 = c1 + c2;
// c3 = operator+(c1, c2);
c3.display();
return 0;
}We can not overload following operators using non member function but these operators can be overloaded as member functions:
- Assignment operator( = )
- Subscript / Index operator( [] )
- Function Call operator[ () ]
- Arrow / Dereferencing operator( -> )
The following operators cannot be overloaded either as member functions or as non-member functions:
- dot/member selection operator( . )
- Pointer to member selection operator(.*)
- Scope resolution operator( :: )
- Ternary/conditional operator( ? : )
- sizeof() operator
- typeid() operator
- static_cast operator
- dynamic_cast operator
- const_cast operator
- reinterpret_cast operator
Constructors
Constructor is a special method that is invoked automatically at the time of object creation. It is used to initialize the data members of new objects. Constructor do not return value, hence they do not have a return type. If we do not specify a constructor, C++ compiler generates a default constructor for the object. Constructor has same name as the class itself. We can not declare constructor as static, constant, volatile or virtual. However, constructors can be declared as inline. They are designed to be called implicitly.
Types of constructor
- Default constructor: A constructor which has no argument is known as default constructor. It is invoked at the time of creating object.
- Parameterized constructor: A constructor which has parameters is called parameterized constructor. It is used to provide different values to distinct objects.
- Copy constructor: A copy constructor is a member function that initializes an object using another object of the same class.
#include <iostream>
using namespace std;
class Rectangle{
int length;
int breadth;
public:
Rectangle(){ //Default constructor
length =1;
breadth =1;
}
Rectangle(int l,int b){ //Parameterised constructor
setLength(l);
setBreadth(b);
}
Rectangle(Rectangle &r){ //Copy constructor
length=r.length;
breadth=r.breadth;
}
void setLength(int l){
if(l>=0)
length=l;
else
length=0;
}
void setBreadth(int b){
if(b>=0)
breadth=b;
else
breadth=0;
}
int getLength(){
return length;
}
int getBreadth(){
return breadth;
}
int area(){
return length*breadth;
}
};
int main(){
Rectangle r1,r2(10,5),r3(r2);
cout<<r1.area()<<endl;
cout<<r2.area()<<endl;
cout<<r3.area()<<endl;
return 0;
}How constructors are different from a normal member function?
- Constructor has same name as the class itself.
- Constructors don’t have return type.
- A constructor is automatically called when an object is created.
- If we do not specify a constructor, C++ compiler generates a default constructor for us.
Destructor
A destructor works opposite to constructor. Destructor destroys the class objects created by constructor. Like constructors, it is invoked automatically. Destructor release memory space occupied by the objects created by constructor. It is designed to call implicitly. If we do not define destructor inside class then compiler generates default destructor for the class.
Can we overload the constructor and destructor in a class?
We can overload the constructor in a class. In fact, the default constructor, parameterized constructor, and copy constructor are the overloaded forms of the constructor but a destructor cannot be overloaded in a class. There can only be one destructor present in a class.
Can constructor be made private?
Yes, Constructor can be defined in private section of class
How to use Constructors in private section?
Using Friend Class
#include <iostream>
using namespace std;
class A{
private:
A(){
cout << "constructor of A\n";
}
friend class B;
};
class B{
public:
B(){
A a1;
cout << "constructor of B\n";
}
};
int main(){
B b1;
return 0;
}
// Output: constructor of A
constructor of BAccess Modifiers in C++
Access modifiers control the visibility and accessibility of classes, methods, variables, and other members within a program.
There are 3 types of access modifiers available in C++:
- Public: Public access modifiers allow the members to be accessed from anywhere within the program. They have the highest level of visibility and can be accessed by other classes and objects.
- Private: Private access modifiers restrict the visibility of members to within the class in which they are declared. Private members cannot be accessed or modified by any other class or object, including subclasses.
- Protected: The protected members can be accessed within the class and from the derived class. The protected access modifier is similar to the private access modifier in the sense that it can’t be accessed outside of its class unless with the help of a friend class.
Note: If we use these keywords to extends the class then it is called as mode of inheritance. If we do not specify any mode, then default mode of inheritance is private.
Scope Resolution Operator
The scope resolution operator is ::. It is used for the following purposes.
- To access a global variable when there is a local variable with same name.
- To define a function outside a class.
- To access a class’s static variables.
- To access the namespace variable.
- In the case of having the same method in both the base and derived classes, we could refer to each by the scope resolution operator.
Namespace
Namespace is used to prevent name conflicts / collision / ambiguity in large projects. We can not define namespace inside function/class. We can not define main function inside namespace. If we define member without namespace then it is considered as member of global namespace. If name of the namespaces are same then name of members must be different.
#include <iostream>
using namespace std;
namespace First {
void fun() {
cout << "First";
}
}
namespace Second {
void fun() {
cout << "Second";
}
}
int main() {
Second::fun(); // Calls the fun() function from the Second namespace
return 0;
}Inline functions
C++ provides inline functions to reduce the function call overhead. An inline function is a function that is expanded in line when it is called. When the inline function is called whole code of the inline function gets inserted or substituted at the point of the inline function call. This substitution is performed by the C++ compiler at compile time. We can use the inline function when performance is needed. We can use the inline function over macros.

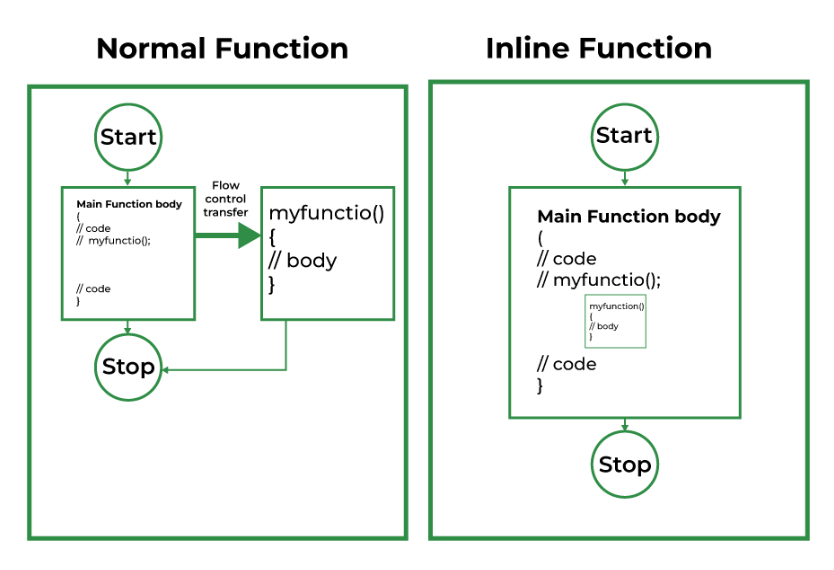
The compiler may not perform inlining in such circumstances as:
- If a function contains a loop.
- If a function contains static variables.
- If a function is recursive.
- If a function return type is other than void, and the return statement doesn’t exist in a function body.
- If a function contains a switch or goto statement.
#include <iostream>
using namespace std;
inline int cube(int s){
return s * s * s;
}
int main(){
cout << "The cube of 3 is: " << cube(3) << "\n";
return 0;
}Struct vs Class
| Struct | Class |
|---|---|
| It is declared using the struct keyword. | It is declared using the class keyword |
| Can have only public members by default | Can have public, private, and protected members |
| Does not support inheritance by default | Supports inheritance |
| Members of a structure are public by default | Members of a class are private by default |
| No default constructor provided automatically | A default constructor is provided by the compiler if not explicitly defined |
| Cannot have member functions with the same name but different parameters | Can have member functions with the same name but different parameters (function overloading) |
C Structures vs C++ Structures
| C Structures | C++ Structures |
|---|---|
| Only data members are allowed, it cannot have member functions. | Can hold both: member functions and data members. |
| Cannot have static members. | Can have static members. |
| Cannot have a constructor inside a structure. | Constructor creation is allowed. |
| Direct Initialization of data members is not possible. | Direct Initialization of data members is possible. |
| Writing the ‘struct’ keyword is necessary to declare structure-type variables. | Writing the ‘struct’ keyword is not necessary to declare structure-type variables. |
| Do not have access modifiers. | Supports access modifiers. |
| Only pointers to structs are allowed. | Can have both pointers and references to the struct. |
| Data Hiding is not possible. | Data Hiding is possible. |
Note: Both in C and C++, members of the structure have public visibility by default.
C vs C++
| C | C++ |
|---|---|
| Procedural programming paradigm | Multi-paradigm programming language (supports procedural, object-oriented) |
| Does not have built-in support for OOP concepts | Provides extensive support for OOP concepts |
| Developed by Dennis Ritchie | Developed by Bjarne Stroustrup |
| Does not support function and operator overloading | Supports function and operator overloading |
| Lacks built-in exception handling mechanisms | Provides exception handling with try-catch blocks to handle and propagate errors |
| C language uses the <stdio.h> header file. | C++ language uses the <iostream.h> header file. |
| C code can be compiled and executed by C++ compilers | C++ code may not be compatible with C compilers due to additional language features |
| Reference variables are not supported in C language. | C++ supports the reference variables. |
| C follows the top-down approach. | C++ follows the bottom-up approach. |
Object-oriented programming vs Procedural programming
| Object-oriented Programming | Procedural Programming |
|---|---|
| It follows a bottom-up approach. | It follows a top-down approach. |
| It provides data hiding. | Data hiding is not allowed. |
| It allows reusability of code | Using functions we can achieve code reusability, but reusability is limited. |
| It is based on objects rather than functions and procedures. | It provides a logical structure to a program in which the program is divided into functions. |
| It provides more security as it has a data hiding feature. | No security |
| More abstraction more flexibility. | Less abstraction less flexibility. |
| “Simula” is considered as first high level OOP language. | “FORTRAN” is considered as first high level POP language. |
Accessors and Mutators
Accessors and Mutators are used to access and modify the private data members of a class. These methods are also called getters and setters since they help get and set the object’s private variables.
#include<iostream>
using namespace std;
class Rectangle{
private:
int length;
int breadth;
public:
void setLength(int l){
length = l;
}
void setBreadth(int b){
breadth = b;
}
int getLength(){
return length;
}
int getBreadth(){
return breadth;
}
int area(){
return length*breadth;
}
int perimeter(){
return 2*(length+breadth);
}
};
int main(){
Rectangle r1;
r1.setLength(10);
r1.setBreadth(5);
cout<<r1.area()<<endl;
cout<<r1.perimeter()<<endl;
cout<<r1.getLength()<<endl;
} This Keyword
this is a keyword that refers to the current instance of the class.
Main usage of this keyword:
- Resolving Variable Shadowing: Variable shadowing occurs when a class member variable and another parameter variable or local variable have the same name. The local variable ‘shadows’ the class member variable.
- We can use the ‘this’ keyword to access the objects that are currently in memory and can further manipulate them.
class Employee {
public:
int id;
string name;
float salary;
Employee(int id, string name, float salary)
{
this->id = id;
this->name = name;
this->salary = salary;
}
void display()
{
cout<<id<<" "<<name<<" "<<salary<<endl;
}
}; Friend Function and Class
A friend function is a function that can access private, protected and public members of a class from non-member functions. The friend function is declared using the friend keyword inside the body of the class.
#include<iostream>
using namespace std;
class Test {
private:
int num;
public:
Test() {
this->num = 10;
}
Test(int num) {
this->num = num;
}
// Member function to display num1
void disp();
// Friend function declaration
friend void print();
};
void Test::disp() {
cout << "T0 : Num : " << this->num << endl;
}
void print() {
Test t1;
t1.num = 600; // Accessing private member directly
cout << "T1 : Num : " << t1.num << endl;
Test t2;
cout << "T2 : Num : " << t2.num << endl;
Test t3(40);
cout << "T3 : Num : " << t3.num << endl;
}
int main(void) {
Test t0;
// t0.num = 400; // This line would cause an error because num1 is private
t0.disp();
print();
return 0;
}#include <iostream>
using namespace std;
class Your;
class My{
private:int a;
protected:int b;
public:int c;
friend Your;
};
class Your{
public:
My m;
void fun(){
m.a=5;
m.b=6;
m.c=7;
cout<<m.a<<endl;
cout<<m.b<<endl;
cout<<m.c<<endl;
}
};
int main(){
Your y;
y.fun();
return 0;
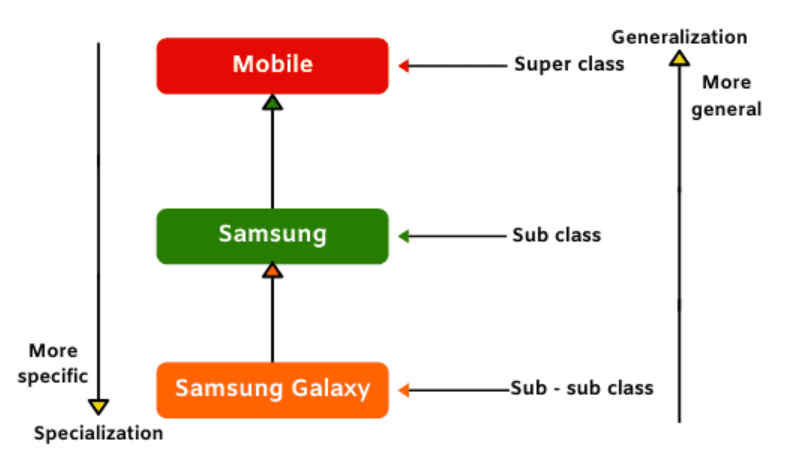
}Generalization and Specialization

Is-A and Has-A
These are two common forms of relationship between two classes:
- The IS-A relationship refers to a class W which is a class Z, probably because class W is a subclass of class Z. For example, a Tomato is a vegetable, a TV is an electronic device. An Is-A relationship is also known as inheritance.
- The Has-A relationship meaning is that an instance of one class has a reference to an instance of another class. For example, a Bus has an engine, a Cow has a tail. The Has-A relationship is also known as composition.
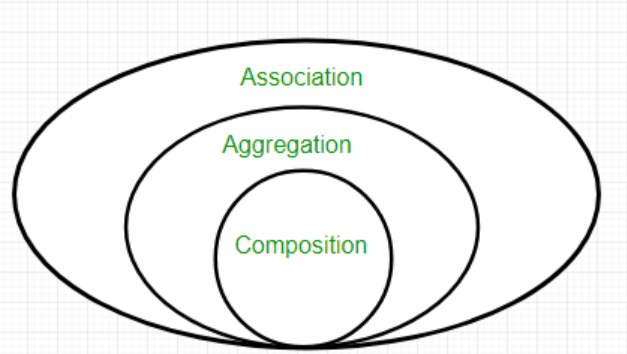
Association, Aggregation and Composition

An association is a relationship between two classes where one class “has a” relationship with the other class. In other words, an instance of one class has an instance of the other class as a member. If has-a relationship exist between two types then we should use association.
class Address {
// Class members and methods
};
class Person {
Address address;
// Class members and methods
};Composition is a special type of association between classes that represents a stronger relationship than a regular association. In a composition relationship, one class is the owner of the other class and is responsible for its creation and destruction. Composition represents tight coupling. For ex, car “has a” engine.
Aggregation is a special type of association between classes that represents a weaker relationship than a composition. In an aggregation relationship, one class is a container for objects of another class, but it is not responsible for the creation or destruction of those objects. Aggregation represents loose coupling. For ex, department “has many” employees. (The contained objects employees can exist independently of the containing object Department, and if the Department object is destroyed, the Employee objects are not automatically destroyed along with it.)
Interface
Interfaces describes the behavior of a class without committing to the implementation of the class. In C++, there is no built-in concept of interfaces. In order to create an interface, we need to create an abstract class which is having only pure virtual methods. In C++, Interfaces are also called pure abstract classes.
Abstract Class
An abstract class is a class that is specially designed to be used as a base class. Abstract class must have at least one pure virtual function. It may have variables and normal functions. The derived classes of an abstract class must implement all the pure virtual functions of their base class or else they too become abstract.
Function Overriding
If derived class defines same function as defined in its base class, it is known as function overriding in C++. It is used to achieve runtime polymorphism.
#include <iostream>
using namespace std;
class Base{
public:
void display(){
cout<<"Display of Base"<<endl;
}
};
class Derived:public Base{
public:
void display(){
cout<<"Display of Derived"<<endl;
}
};
int main(){
Derived d;
d.display();
Base* a = new Base();
a->display();
return 0;
}
Output: Display of Derived
Display of BaseUpcasting
Upcasting is something that occurs automatically, without us having to manually cast it. It occurs when we create a Base Class pointer, and treat it like a pointer to the Child Class object. Upcasting is safe casting as compare to downcasting.
Base *ptr = &derived_obj; #include <iostream>
using namespace std;
class Base{
public:
void fun1(){
cout<<"fun1 of Base"<<endl;
}
};
class Derived : public Base{
public:
void fun2(){
cout<<"fun2 of Derived"<<endl;
}
};
int main(){
Derived d;
Base* ptr=&d; // Object slicing
ptr->fun1();
// ptr->fun2(); this function cannot be call
return 0;
}
//Output: fun1 of BaseNote:
- A pointer of one class can point to other class, but classes must be a base and derived class, then it is possible.
- To access the variable of the base class, base class pointer will be used.
- So, a pointer is type of base class, and it can access all, public function and variables of base class since pointer is of base class, this is known as binding pointer.
Downcasting
Downcasting is an opposite process for upcasting. Downcasting is not as safe as Upcasting, hence it will thrown an error if an implicit conversion is attempted. In order to perform Downcasting, you need to forcefully cast it.
Derived *d_ptr = &b_obj;#include<iostream>
using namespace std;
class BasicCar{
public:
void start(){
cout<<"Car Started"<<endl;
}
};
class AdvanceCar:public BasicCar{
public:
void start(){
cout<<"Playing Music"<<endl;
}
};
int main(){
BasicCar b;
AdvanceCar *q= (AdvanceCar *)&b;
q->start();
}
//Output -> Playing MusicUpcasting and Downcasting Example:
#include <iostream>
using namespace std;
class Parent {
public:
void showid (){
cout << " I am in the Parent class " << endl;
}
};
class Myson : public Parent {
public:
void disp (){
cout << " I am in the Myson class " << endl;
}
};
int main (){
Parent par_obj;
Myson my_obj;
// upcast - here upcasting can be done implicitly
Parent *ptr1 = &my_obj; // base class's reference the derive class's object
// downcast - here typecasting is done explicitly
Myson *ptr2 = (Myson *) &par_obj;
// Upcasting is safe:
ptr1->showid();
ptr2->showid();
// downcasting is unsafe:
ptr2->disp();
return 0;
}
Output: I am in the Parent class
I am in the Parent class
I am in the Myson classVirtual function
A virtual function is a member function that is declared within a base class and is re-defined (overridden) by a derived class. When you refer to a derived class object using a pointer, you can call a virtual function for that object and execute the derived class’s version of the method.
Basically it is a way to achieve runtime polymorphism
#include <iostream>
using namespace std;
class Base{
public:
virtual void display(){
cout<<"Display of Base"<<endl;
}
};
class Derived:public Base{
public:
void display(){
cout<<"Display of Derived"<<endl;
}
};
int main(){
Derived d;
d.display();
Base* ptr=&d;
ptr->display();
return 0;
}
//Output -> Display of Derived
Display of DerivedPure virtual function
- A pure virtual function is a function where we only declare the function but not the function definition. The implementation for pure virtual methods is done at the derived class by function overriding.
- If a class is having pure virtual function then that class is called abstract class. We cannot create object of that class.
#include <iostream>
using namespace std;
class Base{
public:
virtual void fun1()=0; //pure virtual function
virtual void fun2()=0;
};
class Derived : public Base{
public:
void fun1(){
cout<<"fun1 of derived"<<endl;
}
void fun2(){
cout<<"fun2 of derived"<<endl;
}
};
int main(){
Derived d;
d.fun1();
d.fun2();
return 0;
}Practice Example
#include <iostream>
using namespace std;
class Animal{
public:
Animal(){
cout<<"I am inside animal constructor"<<endl;
}
virtual void speak(){
cout<<"Speaking"<<endl;
}
};
class Dog : public Animal{
public:
Dog(){
cout<<"I am inside dog constructor"<<endl;
}
void speak(){
cout<<"Barking"<<endl;
}
};
int main(){
Animal* a = new Animal(); //I am inside animal constructor
Dog* d = new Dog(); //I am inside animal constructor
//I am inside dog constructor
Dog* e = (Dog *)new Animal(); //I am inside animal constructor
e->speak(); //Speaking
Animal* an = new Dog(); //I am inside animal constructor
//I am inside dog constructor
an->speak(); //Barking
return 0;
}Early binding and Late binding
Binding refers to the process of converting identifiers (such as variable and performance names) into addresses. Binding is done for each variable and functions. It takes place either at compile time or at runtime.

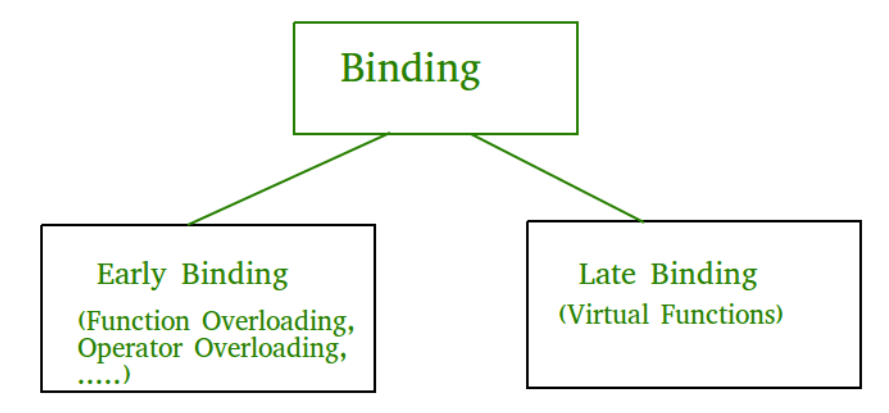
Late Binding
This is run time polymorphism. This is achieved by using virtual function. So whenever we declare a class with virtual function, then C++ compiler during compile time create a static arrays table (function pointer table or virtual table or vtable) and derived class also create its corresponding virtual table. These virtual table contains function pointers. For ex: in Derived class virtual table, there are two function pointers – display that binds to display of derived class because display of base class is virtual and overridden by derived class and sleep that binds to sleep function of base class because this function is not virtual.
In Base class virtual table, there are two function pointers – display that binds to display of base class and sleep that binds to sleep of base class.
C++ compiler also creates a hidden class member pointer called virtual-pointer or in short vptr when there are one or more virtual functions. This vptr is a pointer that points to a table of derived class vtable. This table is created by compiler and called virtual function table or vtable (vtable is created at the compile time).
#include<iostream>
using namespace std;
class Base {
public:
virtual void display() {
cout<<"In Base class" << endl;
}
void sleep(){
cout<<"In Sleep class" << endl;
}
};
class Derived: public Base {
public:
void display() {
cout<<"In Derived class" <<endl;
}
};
int main() {
Base *b = new Derived;
b->display();
b->sleep();
return 0;
}
Output: In Derived class
In Sleep classCan we make virtual constructor?
In C++, constructor cannot be virtual, because when constructor of a class is executed there is no virtual table in the memory, means no virtual pointer defined yet. So, the constructor should always be non-virtual. But virtual destructor is possible.
#include<iostream>
using namespace std;
class Base {
public:
Base()
{
cout<<"Constructing base \n";
}
virtual ~Base(){
cout<<"Destructing base \n";
}
};
class Derived: public Base {
public:
Derived()
{
cout<<"Constructing derived \n";
}
~Derived()
{
cout<<"Destructing derived \n";
}
};
int main(){
Base *b = new Derived();
delete b;
return 0;
}
Output: Constructing base
Constructing derived
Destructing derived
Destructing base
Exception handling
Exception Handling is a process to handle runtime errors. We perform exception handling so the normal flow of the application can be maintained even after runtime errors.
In C++, we use 3 keywords to perform exception handling:
- try: A try block identifies a block of code for which particular exceptions will be activated.
- catch: code that handles the exception thrown by the throw keyword. Single try block may have multiple catch block. A catch block which can handle any type of exception is called generic catch block / catch-all handler.
- throw: throws an exception when an error is detected.
#include <iostream>
using namespace std;
int main(){
int x=10,y=0,z;
try{
if(y==0)
throw 1;
z=x/y;
cout<<z<<endl;
}
catch(int e){
cout<<"Division by Zero"<<e<<endl;
}
cout<<"Bye!"<<endl;
return 0;
}Types of Errors


Syntax errors are also known as the compilation errors as they occurred at the compilation time. These errors are mainly occurred due to the mistakes while typing or do not follow the syntax of the specified programming language. These mistakes are generally made by beginners only because they are new to the language. These errors can be easily debugged or corrected.
Runtime errors: Sometimes the errors exist during the execution-time even after the successful compilation known as run-time errors. When the program is running, and it is not able to perform the operation is the main cause of the run-time error. The division by zero is the common example of the run-time error.
Logical errors: The logical error is an error that leads to an undesired output. These errors produce the incorrect output, but they are error-free, known as logical errors. The occurrence of these errors mainly depends upon the logical thinking of the developer.
// C++ program to demonstrate a logical error
#include <iostream>
using namespace std;
int main() {
int j;
// Cause of Logical error
for(j=0;j<=5;j++);
{
cout << "Hello World";
}
return 0;
}Linker errors: When the program is successfully compiled and attempting to link the different object files with the main object file, errors will occur. When this error occurs, the executable is not generated. This could be due to incorrect function prototyping, an incorrect header file, or other factors. If main() is written as Main(), a linked error will be generated.
Semantic errors: When a sentence is syntactically correct but has no meaning, semantic errors occur. This is similar to grammatical errors. If an expression is entered on the left side of the assignment operator, a semantic error may occur. Semantic errors are the errors that occurred when the statements are not understandable by the compiler.
// C++ program to demonstrate a semantic error
#include <iostream>
using namespace std;
int main() {
int a = 10, b = 20, c;
a + b = c;
cout << c;
return 0;
}Garbage Collection in OOPs world
Object-oriented programming revolves around entities like objects. Each object consumes memory and there can be multiple objects of a class. So if these objects and their memories are not handled properly, then it might lead to certain memory-related errors and the system might fail.
Garbage collection refers to this mechanism of handling the memory in the program. Through garbage collection, the unwanted memory is freed up by removing the objects that are no longer needed
Actual and Formal Parameters
Actual parameters are the values that are passed to a function when it is called. They are also known as arguments.
Formal parameters are the variables declared in the function header that are used to receive the values of the actual parameters passed during function calls. They are also known as function parameters.
Call by Value
- In call by value method, the value of the actual parameters is copied into the formal parameters.
- We can not modify the value of the actual parameter by the formal parameter.
- Any changes made inside functions are not reflected in the actual parameters of the caller.
Call by Reference
- In call by reference, the address of the variable is passed into the function call as the actual parameter.
- The value of the actual parameters can be modified by changing the formal parameters since the address of the actual parameters is passed.
- Any changes made inside the function are actually reflected in the actual parameters of the caller.
#include<iostream>
using namespace std;
// This will not swap a and b
void swap(int a, int b){
int temp = a;
a = b;
b = temp;
}
// Call by reference using pointers
void swapPointer(int* a, int* b){
int temp = *a; //swaping the data
*a = *b;
*b = temp;
}
// Call by reference using C++ reference Variables
void swapReferenceVar(int &a, int &b){
int temp = a;
a = b;
b = temp;
}
int main(){
int x =4, y=5;
cout<<"The value of x is "<<x<<" and the value of y is "<<y<<endl;
// swap(x, y); // This will not swap a and b
// swapPointer(&x, &y); //This will swap a and b using pointer reference
swapReferenceVar(x, y); //This will swap a and b using reference variables
cout<<"The value of x is "<<x<<" and the value of y is "<<y<<endl;
return 0;
}Templates
The simple idea is to pass the data type as a parameter so that we don’t need to write the same code for different data types. For example, a software company may need to sort() for different data types. Rather than writing and maintaining multiple codes, we can write one sort() and pass the datatype as a parameter.
Templates can be represented in two ways:
- Function templates
- Class templates
#include<iostream>
using namespace std;
// int maxim(int a,int b)
// {
// return a>b?a:b;
// }
// float maxim(float a,float b)
// {
// return a>b?a:b;
// }
template<class T>
T maxim(T a,T b)
{
return a>b?a:b;
}
int main(){
cout<<maxim(12,14)<<endl;
cout<<maxim(2.3,1.4)<<endl;
cout<<maxim(2.3f,5.6f)<<endl;
return 0;
} #include<iostream>
using namespace std;
template <class T>
class Array {
private:
int size;
T *arr;
public:
// Default constructor
Array() : size(0), arr(NULL) {}
// Parameterized constructor
Array(int size)
{
this->size = size;
this->arr = new T[this->size];
}
void acceptRecord() {
int i;
cout << "\nEnter Array Elements: ";
for(i = 0; i < this->size; i++)
cin >> arr[i];
}
void printRecord() {
int i;
cout << "Array Elements are : ";
for(i = 0; i < this->size; i++)
cout << arr[i] << " ";
}
~Array() {
cout << "\nDestructor called " << endl;
delete[] arr;
}
};
int main(void) {
Array<char> a1(5); // Creating a character array of size 5
a1.acceptRecord();
a1.printRecord();
Array<int> a2(5); // Creating an integer array of size 4
a2.acceptRecord();
a2.printRecord();
return 0;
}Why Java is not a purely Object-Oriented Language?
Pure Object Oriented Language have features which treats everything inside program as objects. It doesn’t support primitive datatype(like int, char, float, bool, etc.). There are seven qualities to be satisfied for a programming language to be pure Object Oriented. They are:
- Encapsulation
- Inheritance
- Polymorphism
- Abstraction
- All predefined types are objects
- All user defined types are objects
- All operations performed on objects must be only through methods exposed at the objects.
Example: Smalltalk
Java supports property 1, 2, 3, 4 and 6 but fails to support property 5 and 7 given above.
const keyword
The const keyword is used to declare that a variable, function, or object is immutable i.e. it’s value can’t be changed after initialization. constant variable is also called as read only variable. For ex: const int x = 5;
const int i = 3; // VALID
i++; // INVALID
const int val; // INVALIDThis is invalid in C++ because the constant variable val is not initialized. In C++, every const variable must be initialized when it is declared.
constant data member
#include <iostream>
using namespace std;
class Test
{
private:
int num1;
const int val; // constant data member declaration
public:
Test() : num1(10), val(50) {}
// Uncommenting the following constructor will cause a compilation error because we cannot assign a value to a const member in the constructor body.
/*
Test() // NOT ALLOWED
{
this->num1 = 10;
this->val = 50; // error: assignment of read-only member
}
*/
// This constructor is allowed. It initializes the const member using an initializer list.
// The non-const member is assigned a value in the constructor body.
/*
Test() : val(50) // ALLOWED Partial Constructor Initializer list
{
this->num1 = 60;
}
*/
void disp()
{
cout << "Num1: " << num1;
cout << " Val: " << val;
this->num1 += 10; // Allowed
// this->val += 20; // Constant value cannot be modified
cout << "\nAfter Modification of Num1: " << num1 << endl;
}
};
int main() {
Test t;
t.disp();
return 0;
}const member function
If we do not want to modify state of current object inside member function then we should declare
member function as constant. In constant member function, if we want to modify state of non constant data member then we should use mutable keyword.
#include <iostream>
using namespace std;
class Demo
{
private:
int num; // non-constant data member
const int c; // constant data member
public:
Demo() : num(30), c(40) {}
// Constant member function
void disp() const
{
cout << "Num: " << num << " C: " << c << endl;
// The following lines are commented out because they will cause errors
// in a constant member function. You cannot modify any member variables.
// num++; // error: increment of member ‘Demo::num’ in read-only object
// c++; // error: increment of read-only member ‘Demo::c’
// cout << "After Num++ " << num << endl;
}
};
int main() {
Demo dobj;
dobj.disp();
return 0;
}Note: We can not declare following function constant:
- Global Function
- Static Member Function
- Constructor
- Destructor
Mutable data members are those members whose values can be changed in runtime even if the object is of constant type. It is just opposite to constant.
#include <iostream>
using namespace std;
class Demo
{
private:
int num; // Non-constant data member
const int c; // Constant data member
mutable int m; // Mutable data member
public:
Demo() : num(30), c(40), m(50) {}
// Constant member function
void disp() const
{
cout << "Num: " << num << " C: " << c << " M: " << m << endl;
// num++; // Error: increment of member ‘Demo::num’ in read-only object
// c++; // Error: increment of read-only member ‘Demo::c’
m++; // Mutable member can be modified even in a const member function
// Displaying values after modifying the mutable member
cout << "Num: " << num << " C: " << c << " M: " << m << endl;
}
};
int main() {
Demo dobj;
dobj.disp();
return 0;
}lvalue and rvalue
lvalue – variable having memory location. Ex: int x, char x
rvalue – variable don’t have memory location. Ex: 5, int &a = b;
Preprocessors
Preprocessors are programs that process the source code before compilation.
Preprocessor programs provide preprocessor directives that tell the compiler to preprocess the source code before compiling. All of these preprocessor directives begin with a ‘#’ (hash) symbol.
Types of Preprocessor Directives:
Macros
Macros are preprocessor directives that allow you to define constants, functions, or code snippets that can be used throughout our code. They are typically defined using the #define directive and are evaluated by the preprocessor before the code is compiled.
// Example 1:
#include <iostream>
using namespace std;
#define max(a,b) (a>b?a:b)
#define msg(x) #x
#define msg2(x) #x + 3
#define PI 3.1425
int main(){
cout << PI << endl;
cout << max(10,12) << endl;
cout << msg(hello) << endl;
cout << msg2(hello) << endl;
return 0;
}
// Example 2:
#include <stdio.h>
#define SQR(a) a*a
int main() {
printf("%d", SQR(3 + 2));
// 3 + 2 * 3 + 2
// 3 + 6 + 2
// 11
return 0;
}File Inclusion
This type of preprocessor directive tells the compiler to include a file in the source code program. The #include preprocessor directive is used to include the header files.
#include <file_name>Note: Can you compile a program without the main function?
Yes, it is absolutely possible to compile a program without a main(). For example Use Macros that defines the main().
Conditional Compilation
Conditional Compilation is a type of directive that helps to compile a specific portion of the program or to skip the compilation of some specific part of the program based on some conditions.
#include <stdio.h>
#define PI 3.14
int main() {
#if defined(PI)
printf("PI is defined");
#else
printf("PI is not defined");
#endif
#undef PI
#if defined(PI)
printf("\nPI is defined");
#else
printf("\nPI is not defined");
#endif
#ifndef SQUARE
printf("\nSquare is not defined");
#else
printf("\nSquare is defined");
#endif
return 0;
}Shallow and Deep copy
| Shallow Copy | Deep Copy |
| The changes made in the copied object also reflect the original object. | There is no reflection on the original object when the changes are made in the copied object. |
| Both copied and original object point to same memory location. | Copied and original object does not point to same memory location. |
| Shallow copy is faster than Deep copy. | Deep copy is slower than Shallow copy. |
| It is also called as bit-wise copy/ bit-by bit copy. | It is also called as member-wise copy. |
| When we assign one object to another object at that time copying all the contents from source object to destination object as it is. Such type of copy is called as shallow copy. | When we assign one object to another object at that time instead of copy base address allocate a new memory for each and every object and then copy contain from memory of source object into memory of destination object. Such type of copy is called as deep copy. |
Note: Conditions to create deep copy – Class must contain at least one pointer type data member.

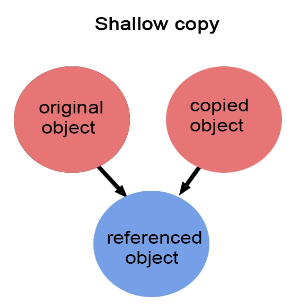

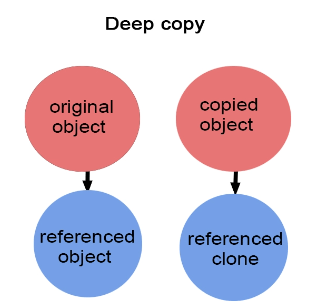
#include <iostream>
using namespace std;
class abc{
public:
int x;
int *y;
abc(int _x, int _y){
x = _x;
y = new int(_y);
}
// default dumb copy constructor -> it does shallow copy
abc(const abc &obj){
x = obj.x;
y = obj.y;
}
// deep copy
// abc(const abc &obj){
// x = obj.x;
// y = new int(*obj.y);
// }
int print() const{
printf("X: %d\nptr Y: %d\n*Y: %d\n",x,y,*y);
}
};
int main(){
abc a(1, 2);
cout<<"Printing a: "<<endl;
a.print();
abc b(a); // Copy constructor
cout<<"Printing b: "<<endl;
b.print();
*b.y = 3;
cout<<"Printing b: "<<endl;
b.print();
cout<<"Printing a: "<<endl;
a.print();
return 0;
}
// We can see on changing the value of b, the value of a also changes but we want b as a independent object(this is because of shallow copy)Global Variables
- Global variables are declared outside all the function blocks.
- Any change in global variable affects the whole program, wherever it is being used.
- It can be accessed throughout the program by all the functions present in the program.
- If the global variable is not initialized, it takes zero by default.
- Global variables are stored in the data segment of memory.
- We cannot declare many variables with the same name.
Local Variables
Local Variables are declared within a function block.
- Any change in the local variable does not affect other functions of the program.
- A local variable is created when the function is executed, and once the execution is finished, the variable is destroyed.
- It can only be accessed by the function statements in which it is declared and not by the other functions.
- If the local variable is not initialized, it takes the garbage value by default.
- Local variables are stored in a stack in memory.
- We can declare various variables with the same name but in other functions.
#include <iostream>
using namespace std;
// Global variable declaration:
int g = 20;
int main () {
// Local variable declaration:
int g = 10;
cout << g; // Local
cout << ::g; // Global
return 0;
}Static Data Members or Static Member Function
- Static data members are class members that are declared using static keyword.
- Only one copy of that member is created for the entire class and is shared by all the objects of that class, no matter how many objects are created.
- It is initialized before any object of this class is created, even before the main starts.
- Static variable is also called as shared variable.
- Uninitialized static and global variable get space on BSS segment while initialized static and global variable get space on Data segment.
- Default value of static and global variable is zero.
- Static variables are same as global variables but it is having limited scope.
- static member function can access only static data members of a class.
- static member function is also called as class level method.
- static variables, if declared within block, limited to a block scope and if declared outside function, limited to file scope.

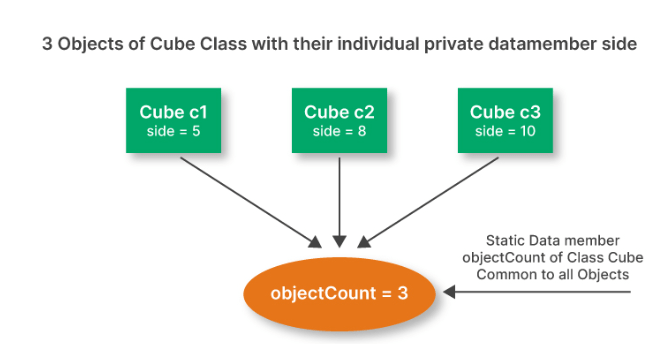
Note: Static data member in C++ does not contain a this pointer. The this pointer is a pointer to the current object, and it is only available in non-static member functions. Static data members are shared among all objects of a class, and they do not have a this pointer.
Example:
#include <iostream>
using namespace std;
class abc{
public:
static int x, y;
void print(){
cout<<x<<" "<<y<<endl;
}
// This will show error because static member function can access only static data members of a class
// int x, y;
// static void print(){
// cout<<x<<" "<<y<<endl;
// }
};
int abc::x;
int abc::y;
int main(){
abc obj1;
obj1.x = 1;
obj1.y = 2;
obj1.print();
abc obj2;
obj2.x = 10;
obj2.y = 20;
obj1.print();
obj2.print();
return 0;
}How delete [] is different from delete?
Delete is used to release a unit of memory, delete[] is used to release an array.
int value=new int; //allocates memory for storing 1 integer
delete value; // deallocates memory taken by value
int *arr=new int[10]; //allocates memory for storing 10 int
delete []arr; // deallocates memory occupied by arrDifference between reference and pointer
| Reference | Pointer |
|---|---|
Declared using & symbol | Declared using * symbol |
| Reference behaves like an alias for an existing variable, i.e., same memory location but different names. | The pointer is a variable which stores the address of a another variable. |
| Reference does not have a memory address | Pointer holds the memory address (8) |
| A null value cannot be assigned to the reference variable, must always refer to a valid object. | We can initialized pointer to NULL. |
| Cannot be re-assigned to refer to a different object | Can be re-assigned to point to different memory locations. |
| We can’t create reference to reference. | We can create pointer to pointer (double pointer) |
int x = 10; int &y = x; | int x = 10; int *ptr = &x; |
Note: Using typedef we can create alias for classes, structures whereas using reference we can create alias for object.
Difference between new() and malloc()
| new | malloc |
| C++ | C |
| new() is a preprocessor | malloc() is a function |
| Allocates memory and calls the constructor for the object initialization | malloc() function allocates the memory but does not call the constructor for the object initialization. |
| no need to allocate the memory while using “new” | in malloc() you have to use sizeof() |
| The new() operator is faster than the malloc() function as operator is faster than the function | slower |
int *ptr = new int(5); | int *ptr = (int*)malloc(sizeof(int)); |
#include <iostream>
using namespace std;
int main() {
int *ptr = new int; // Allocate memory for an int on the heap
*ptr = 123; // Assign the value 123 to the allocated memory
cout << "Value: " << *ptr << endl;
delete ptr; // Deallocate the memory
ptr = nullptr; // Set the pointer to nullptr to avoid a dangling pointer
return 0;
}Typecasting
A type cast is basically a conversion from one type to another. There are two types of type conversion: Implicit Type Conversion (automatically by the compiler) & Explicit Type Conversion (manually by the compiler). Type Casting is also known as Type Conversion.
// Implicit
char ch = 97;
cout << ch;
// Output: a
// Explicit
double d = 5.7
int x = (int)d + 2;
cout << x;
// Output: 7Compiler and Interpreter
The Compiler and Interpreter, both have similar works to perform. Interpreters and Compilers convert the Source Code (HLL) to Machine Code (understandable by Computer).
| Interpreter | Compiler |
|---|---|
| Translates program one statement at a time. | Scans the entire program and translates it as a whole into machine code. |
| Display all errors of each line one by one. | Display all errors after compilation, all at the same time. |
| The interpreter does not generate any output file. | The compiler generates an output in the form of (.exe) file. |
| Programming languages like JavaScript, Python, PHP use interpreters. | Programming languages like C, C++, C# use compilers. |
| Any change in the source program during the translation does not require retranslation of the entire code. | Any change in the source program after the compilation requires recompiling the entire code. |
| CPU utilization is less in the case of a Interpreter. | CPU utilization is more in the case of a Compiler. |
| No Intermediate object code is generated. | Intermediate object code is generated. |
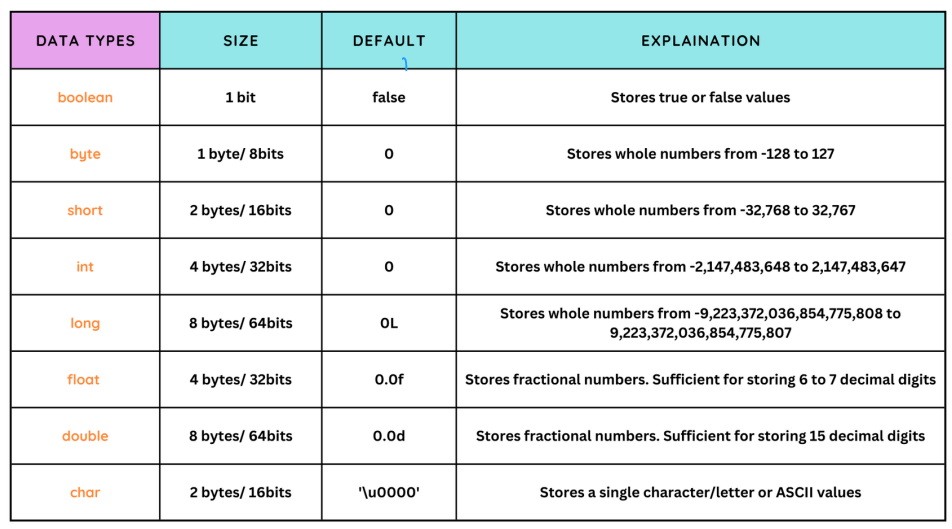
Data Types


| Data Type | Size (bytes) | Range | Format Specifier |
|---|---|---|---|
| short int | 2 | -32,768 to 32,767 | %hd |
| unsigned short int | 2 | 0 to 65,535 | %hu |
| unsigned int | 4 | 0 to 4,294,967,295 | %u |
| int | 4 | -2,147,483,648 to 2,147,483,647 | %d |
| long int | 4 | -2,147,483,648 to 2,147,483,647 | %ld |
| unsigned long int | 4 | 0 to 4,294,967,295 | %lu |
| long long int | 8 | -(2^63) to (2^63)-1 | %lld |
| unsigned long long int | 8 | 0 to 18,446,744,073,709,551,615 | %llu |
| signed char | 1 | -128 to 127 | %c |
| unsigned char | 1 | 0 to 255 | %c |
| float | 4 | 1.2E-38 to 3.4E+38 | %f |
| double | 8 | 1.7E-308 to 1.7E+308 | %lf |
| long double | 16 | 3.4E-4932 to 1.1E+4932 | %Lf |
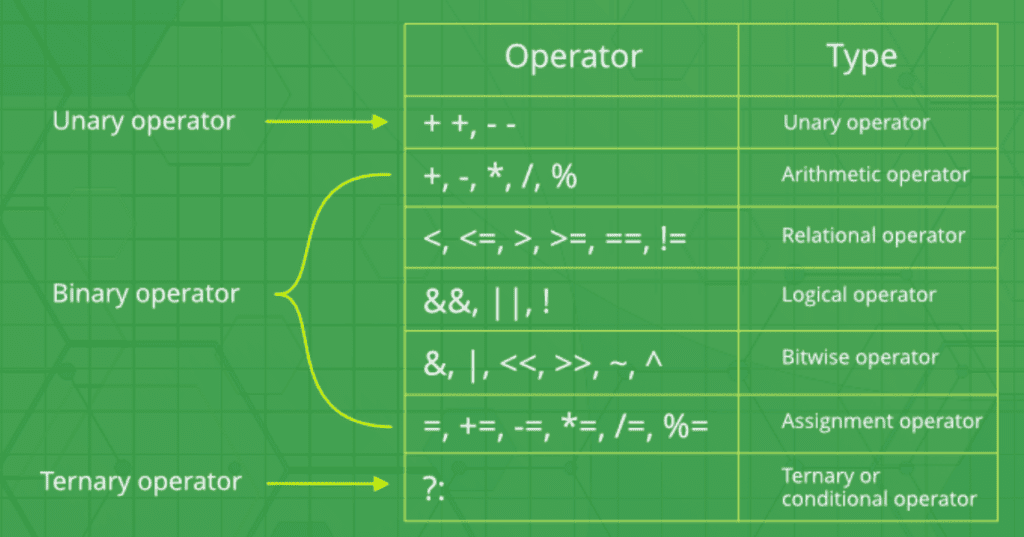
Operators in C++
An operator is a symbol that operates on a value to perform specific mathematical or logical computations.
int c = a + b;Operators in C++ can be classified into 6 types:
- Arithmetic Operators
- Relational Operators
- Logical Operators
- Bitwise Operators
- Assignment Operators
- Ternary or Conditional Operators



Tokens
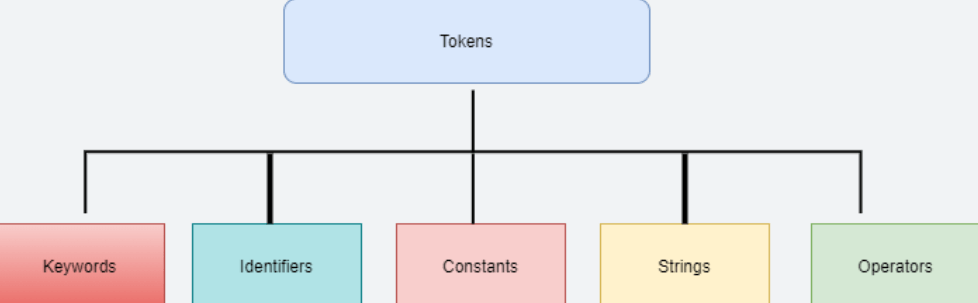
A token is the smallest individual element of a program that is understood by a compiler.

Keywords in C++
Keywords are predefined, reserved words used in programming that have special meanings to the compiler. Keywords are part of the syntax and they cannot be used as an identifier. The total count of reserved keywords is 95. All C++ variables must be identified with unique names. These unique names are called identifiers.
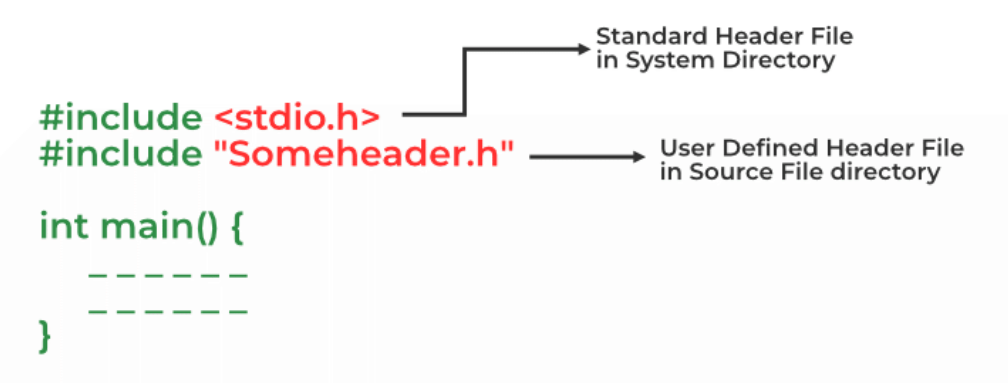
#include<> and #include””
The difference between #include<> and #include is in the location where the preprocessor searches for the file to be included in the code:
#include<filename.h>
- This is used to include system header files.
- System header files are located in standard directories that are known to the compiler.
- For example, #include<stdio.h> includes the standard input/output header file.
#include”filename.h”
- This is used to include user-defined header files.
- User-defined header files are located in the same directory as the source file that includes them.
- For example, #include”myheader.h” includes the header file myheader.h, which is located in the same directory as the source file.

High Level Language vs Low level Language
| High level language is less memory efficient. | Low level language is high memory efficient. |
| It is easy to understand. | It is tough to understand. |
| Debugging is easy. | Debugging is complex comparatively. |
| It is programmer friendly language. | It is a machine friendly language. |
| It can run on any platform. | It is machine-dependent. |
| It needs compiler or interpreter for translation. | It needs assembler for translation. |
| It is used widely for programming. | It is not commonly used now-a-days in programming. |
Storage Classes
Storage Classes are used to describe the characteristics of a variable/function. It determines the lifetime, visibility, default value, and storage location which helps us to trace the existence of a particular variable during the runtime of a program.
| Storage Class | Keyword | Lifetime | Visibility | Initial Value | Storage |
|---|---|---|---|---|---|
| Automatic/local | auto | Function Block | Local | Garbage | stack |
| Register | register | Function Block | Local | Garbage | CPU register |
| Mutable | mutable | Class | Local | Garbage | stack |
| External/global | extern | Whole Program | Global | Zero | data segment |
| Static | static | Whole Program | Local | Zero | data segment |
Note: There is no guarantee that our register request will be entertained. As number of registers availability is very less our request may be rejected and it will be automatically converted in auto type. An important and interesting point to be noted here is that we cannot obtain the address of a register variable using pointers. Use of register in global section is not allowed.
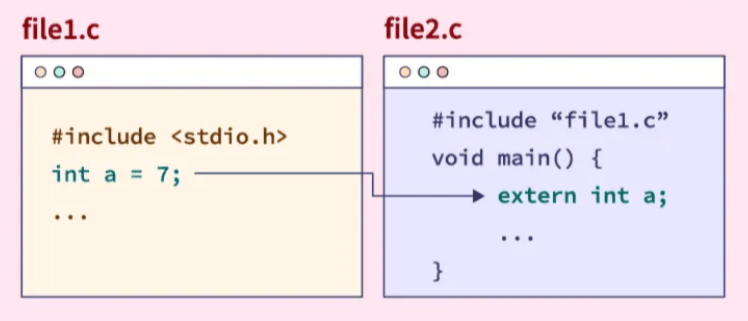
Note: GLOBAL variables are declared in one file. But they can be accessed in another file only with the EXTERN keyword. In the same file, no need of EXTERN.

Literals In C++
Literals are fundamental elements used to represent constant values used in C++ programming language. These constants can include numbers, characters, strings, and more.

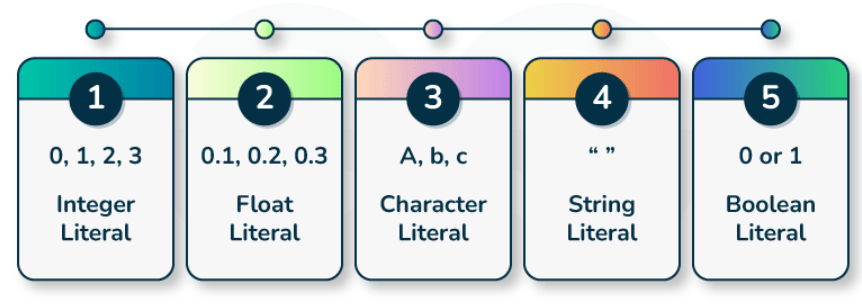
Integer Literals
Integer literals in C++ are constants that represent whole numbers without the fractional or decimal part. They can be positive or negative and can have different bases such as decimal, octal, or hexadecimal.
int integerLiteral = 42;
In C++, integer literals can be categorized into various types based on their bases.
Decimal Literal: The decimal literal represents an integer in base 10 without any prefix.
int decimal = 42;
Octal Literal (Prefix: 0): The octal literal represents an integer in base 8 and is preceded by the 0 prefix.
int octal = 052; // 42 in decimal
Hexadecimal Literal (Prefix: 0x or 0X): The hexadecimal literal represents an integer in the base 16 and is preceded by either 0x or 0X prefix.
int hexadecimal = 0x2A; // 42 in decimal
Binary Literal (Suffix: b or B): The binary literal represents an integer in the base 2 and can have a suffix of b or B.
int binary = 0b101010; // 42 in decimal
Long Integer Literal (Suffix: l or L): The long integer literal can be suffixed with the l or L to indicate that it is of type long int.
long int longInteger = 42L;
Unsigned Integer Literal (Suffix: u or U): The unsigned integer literal can be suffixed with the u or U to indicate that it is of type unsigned int.
unsigned int unsignedInt = 42U;
Long Long Integer Literal (Suffix: ll or LL): The long long integer literal can be suffixed with the ll or LL to indicate that it is of type long long int.
long long int longLongInteger = 42LL;
Floating-Point Literals
The Floating-point literals in C++ are constants that represent numbers with the fractional or decimal part. These can be either single-precision or double-precision values.
double floatLiteral = 3.14;
Character Literals
The Character literals in C++ are constants that represent individual characters or escape sequences (\n, \t, \b, \\). They are enclosed in single quotes and you can use them to represent the single character.
char charLiteral = 'A';
String Literals
const char* stringLiteral = "Hello, World!";Boolean Literals
The Boolean literals represent the truth values and have only two possible values: true and false.
#include <iostream>
using namespace std;
int main() {
bool isTrue = true;
bool isFalse = false;
if (isTrue) {
cout << "isTrue is true" << endl;
}
else {
cout << "isTrue is false" << endl;
}
if (isFalse) {
cout << "isFalse is true" << endl;
}
else {
cout << "isFalse is false" << endl;
}
return 0;
}RTTI (Run-time type Information)
RTTI (Run-time type information) is a mechanism that exposes information about an object’s data type at runtime and is available only for the classes which have at least one virtual function. It allows the type of an object to be determined during program execution.
The below code will generate an error like “cannot dynamic_cast base_ptr (of type Base*) to type ‘class Derived*’ (Source type is not polymorphic)”. This error comes because there is no virtual function in this example.
#include <iostream>
using namespace std;
class Base {};
class Derived: public Base {};
int main() {
Base *base_ptr = new Derived;
// Attempt to cast the Base pointer to a Derived pointer using dynamic_cast
Derived *derived_ptr = dynamic_cast<Derived*>(base_ptr);
// Check if the cast was successful
if(derived_ptr != NULL)
cout << "It is working";
else
cout << "cannot cast Base* to Derived*";
delete base_ptr;
return 0;
}Now after adding a virtual method, it will work.
#include <iostream>
using namespace std;
class Base {
virtual void function() {}
};
class Derived: public Base {};
int main() {
Base *base_ptr = new Derived;
// Attempt to cast the Base pointer to a Derived pointer using dynamic_cast
Derived *derived_ptr = dynamic_cast<Derived*>(base_ptr);
// Check if the cast was successful
if(derived_ptr != NULL)
cout << "It is working";
else
cout << "cannot cast Base* to Derived*";
delete base_ptr;
return 0;
}Casting Operators in C++
Casting operators are used for type casting in C++. They are used to convert one data type to another. C++ supports four types of casts:
- static_cast
- dynamic_cast
- const_cast
- reinterpret_cast
The static_cast operator is the most commonly used casting operator in C++. It performs compile-time type conversion and is mainly used for explicit conversions that are considered safe by the compiler.
The dynamic_cast operator is mainly used to perform downcasting (converting a pointer/reference of a base class to a derived class). It ensures type safety by performing a runtime check to verify the validity of the conversion.
If we want to convert pointer to constant object into pointer to non-constant object then we should use this operator. Caution must be exercised when using const_cast, as modifying a const object can lead to undefined behavior.
The reinterpret_cast operator is used to convert the pointer to any other type of pointer. It does not perform any check whether the pointer converted is of the same type or not.
Command Line Arguments
Command-line arguments are arguments that are passed to a program when it is executed from the command line or terminal.
main() function prototypes
int main();
int main(int argc, char *argv[]);
int main(int argc, char *argv[], char *env[]);- argc represents number of arguments passed to program when it is executed from command line.
- argv represents argument vector or argument values.
- env represents system information.
#include <stdio.h>
int main(int argc, char *argv[], char *env[]) {
int i;
printf("Argument count = %d\n", argc);
for(i = 0; i < argc; i++) {
printf("argv[%d] = %s\n", i, argv[i]);
}
for(i = 0; i < 30; i++) {
printf("env[%d] = %s\n", i, env[i]);
}
return 0;
}C++ (platform-dependent) & Java (platform-independent)

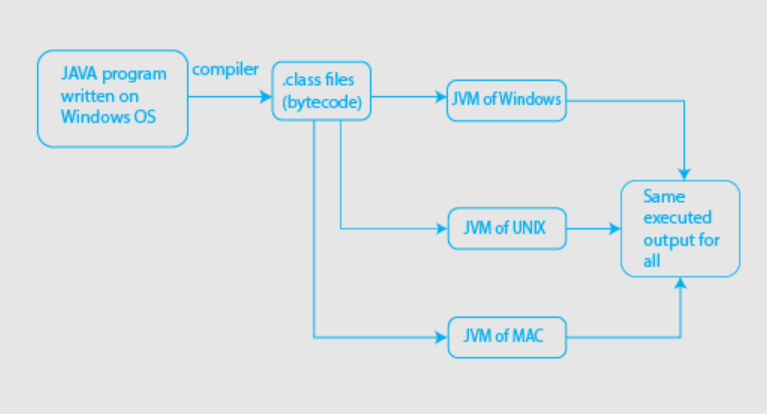

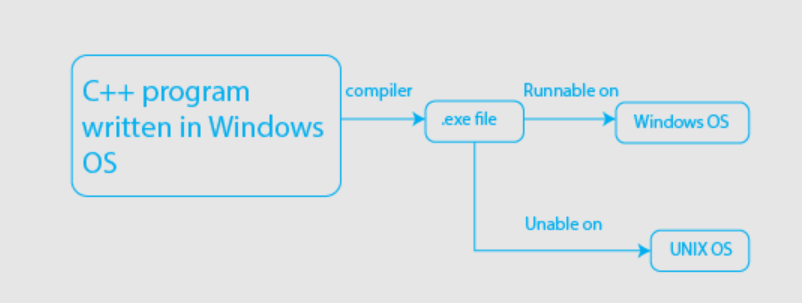
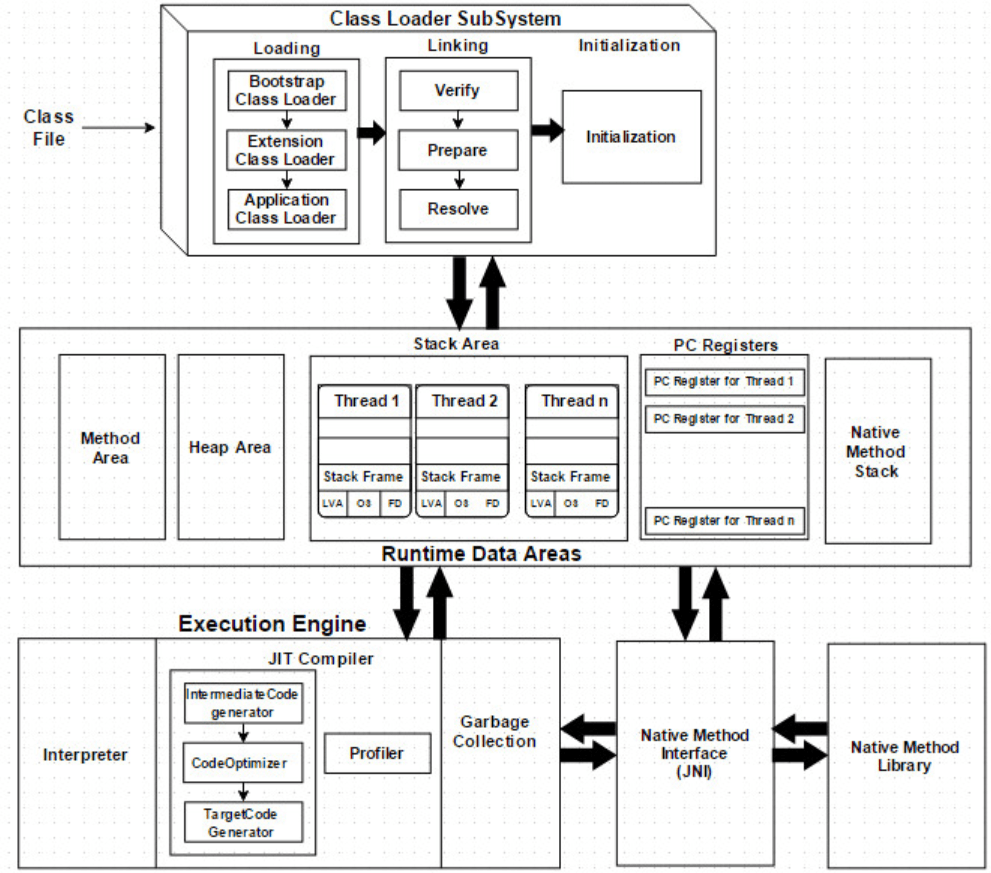
JVM Architecture
JVM(Java Virtual Machine) acts as a run-time engine to run Java applications. JVM is the one that actually calls the main method present in a Java code. JVM is a part of JRE (Java Runtime Environment)